Blogginnlegg 2 NordicNeuroLab
Hei!
Frida her, som er i praksis hos NordicNeuroLab (NNL).
Det nærmer seg slutten på praksis, og det har vært en svært lærerik høst. Jeg har lært mye om fMRI, hvordan analysere bildene som blir generert, og hvordan selve scannene blir tatt. Jeg har også fått mye bruk for tidligere fag, da spesielt STAT110 og PHYS212.
Det har vært veldig interessant og nyttig å få være med på å ta selve scannene av testpersonene. Vi har vært på Haukeland tre ganger i løpet av semesteret og tatt scans. Jeg har fått være med på selve prosessen og hvordan man må stille inn maskinen for å ta bilde på riktig måte. Jeg har også fått mye hjelp av noen av de som jobber i NNL, og en radiograf som jobber på Haukeland. Det har vært gøy å se hvordan det man lærer på studiet brukes i praksis.
Vi har nå tatt fMRI av 5 forskjellige testpersoner. Siden vi har brukt paradigmer som gjelder språk, er det hjerneområdene Brocas og Wernickes som aktiveres. Det er disse hjerneområdene vi hentet ut data om signal fra, og vi brukte disse dataene videre.
Vi har brukt parvise t-tester for å sammenligne de kortere paradigmene som vi lagde med de lange (vanlige) paradigmene. Parvis t-test fungerer kort fortalt slik at man sammenligner gjennomsnitt fra to forskjellige utvalg. Vårt utvalg i dette tilfellet ble da data fra korte vs lange paradigmer. Dataene ble satt samme i samme tabell for å samle data fra alle testpersonene.
For å utføre t-testene brukte vi excel som har en innebygd funksjon for dette. Vi brukte p-verdi 0.05, så dersom vi fikk en p-verdi lavere enn 0.05 betyr det at det var en signifikant forskjell mellom kort og langt paradigme.
Resultatene, som vist nedenfor i excel, viser at det i 12 av 20 tester var signifikant forskjell mellom kort og langt paradigme. Dermed kan vi konkludere med at de korte paradigmene ikke er like gode som de lange paradigmene.
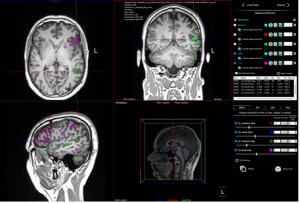
Bildet over viser programmet jeg brukte for å analysere bildene vi tok. Som dere kan se så er det områder som blir akivert, og vi henter ut dataene fra tabellen til høyre.

I bildet ovenfor viser p-verdien fra de ulike t-testene. Jeg delte inn slik at jeg testet hver variabel (gjennomsnitt, standardavvik, min, maks og volum), for hvert paradigme og hvert hjerneområde.